服务器部署知识库(Docker、Nginx)
一、介绍
本章主要讲如何讲项目部署到有公网的服务器上,练习 Linux、Docker、Nginx的线上操作。
在开始前优化上一章节遗留问题:添加模型上下文记忆功能。
修改项目中docs/dev-ops/nginx/html/js/index.js 文件里 startEventStream 方法:
function startEventStream(message) {
if (isStreaming) return;
if (!currentChatId) {
console.error("Cannot start stream without a current chat ID.");
return;
}
setStreamingState(true);
if (currentEventSource) {
currentEventSource.close();
}
const selectedRagTag = ragSelect.value; // Keep RAG selection logic
const selectedAiModelValue = aiModelSelect.value;
const selectedAiModelName = aiModelSelect.options[aiModelSelect.selectedIndex].getAttribute('model');
if (!selectedAiModelName) {
console.error("No AI model name selected!");
setStreamingState(false);
appendMessage("错误:未选择有效的 AI 模型。", true, false);
return;
}
// --- WORKAROUND START ---
// 1. Get chat history
const chatData = getChatData(currentChatId);
const history = chatData ? chatData.messages : [];
// 2. Format history into a single string to prepend
let historyString = "";
// Limit history length to avoid excessively long URLs (adjust maxHistory as needed)
const maxHistory = 10; // Example: Keep last 10 messages
const startIndex = Math.max(0, history.length - maxHistory);
for (let i = startIndex; i < history.length; i++) {
const msg = history[i];
if (typeof msg.content === 'string' && typeof msg.isAssistant === 'boolean') {
// Important: Exclude <think> tags from the history string sent to the model
// unless your model is specifically trained to handle them as part of the prompt.
// Usually, you only want the actual conversation turns.
const contentWithoutThink = msg.content.replace(/<think>.*?<\/think>/gs, '').trim();
if (contentWithoutThink) { // Only add if there's actual content after removing think tags
historyString += (msg.isAssistant ? "Assistant: " : "User: ") + contentWithoutThink + "\n";
}
}
}
// 3. Prepend history to the current message
const combinedMessage = historyString + "User: " + message; // Clearly mark the new message
// --- WORKAROUND END ---
let url;
const base = `http://localhost:7080/api/v1/${selectedAiModelValue}`;
// --- Send the COMBINED message in the 'message' parameter ---
const params = new URLSearchParams({
// Send the combined history+current message string
message: combinedMessage,
model: selectedAiModelName
// NO 'history' parameter here
});
if (selectedRagTag) {
params.append('ragTag', selectedRagTag);
// Decide how RAG interacts with history prepending.
// Does the backend RAG process need the raw message or the combined one?
// Assuming backend handles RAG based on the full 'message' param for now.
url = `${base}/generate_stream_rag?${params.toString()}`;
} else {
url = `${base}/generate_stream?${params.toString()}`;
}
// --- END MODIFICATION ---
console.log("Streaming URL (Workaround):", url); // URL will have a long 'message' param
console.log("Combined Message sent:", combinedMessage); // Log the combined string
currentEventSource = new EventSource(url);
let accumulatedContent = '';
let tempMessageWrapper = null;
let streamEnded = false;
const messageId = `ai-message-${Date.now()}`;
// --- Create Unified Placeholder ---
if (chatArea.style.display === 'none') {
chatArea.style.display = 'block';
welcomeMessage.style.display = 'none';
}
tempMessageWrapper = document.createElement('div');
tempMessageWrapper.className = 'flex w-full mb-4 message-bubble justify-start';
tempMessageWrapper.id = messageId;
tempMessageWrapper.innerHTML = `
<div class="flex gap-3 max-w-4xl w-full">
<div class="w-8 h-8 rounded-full bg-green-100 flex items-center justify-center flex-shrink-0 mt-1 shadow-sm">
<span class="text-green-600 text-sm font-semibold">AI</span>
</div>
<div class="message-content-wrapper bg-white border border-gray-200 px-4 py-3 rounded-lg shadow-sm min-w-[80px] flex-grow markdown-body">
<span class="streaming-cursor animate-pulse">▋</span>
</div>
</div>
`;
chatArea.appendChild(tempMessageWrapper);
let messageContentWrapper = tempMessageWrapper.querySelector('.message-content-wrapper');
let hasInjectedDetails = false;
requestAnimationFrame(() => {
chatArea.scrollTop = chatArea.scrollHeight;
});
// The rest of the onmessage, onerror, DOM handling logic remains the same
// as in the previous snippet. The AI's response (accumulatedContent)
// is still processed and displayed identically.
currentEventSource.onmessage = function (event) {
// ... (SAME onmessage logic as before - handling stream data, <think> tags, DOM updates) ...
if (streamEnded) return;
try {
const data = JSON.parse(event.data);
if (data.result?.output?.text !== undefined) {
const newContent = data.result.output.text ?? '';
accumulatedContent += newContent;
// --- Process Accumulated Content ---
const thinkRegex = /<think>(.*?)<\/think>/gs;
let thinkingSteps = '';
let match;
const localThinkRegex = /<think>(.*?)<\/think>/gs;
while ((match = localThinkRegex.exec(accumulatedContent)) !== null) {
thinkingSteps += match[1] + '\n';
}
thinkingSteps = thinkingSteps.trim();
const finalAnswer = accumulatedContent.replace(/<think>.*?<\/think>/gs, '').trim();
// --- Update DOM Dynamically ---
messageContentWrapper = document.getElementById(messageId)?.querySelector('.message-content-wrapper');
if (!messageContentWrapper) {
console.error("Message wrapper not found!");
return;
}
if (thinkingSteps && !hasInjectedDetails) {
messageContentWrapper.innerHTML = `
<details class="thinking-process" open>
<summary class="cursor-pointer text-sm text-gray-600 hover:text-gray-800 mb-2 focus:outline-none select-none">
思考过程... <span class="text-xs opacity-70">(点击展开/折叠)</span>
</summary>
<div class="thinking-steps-content markdown-body border-t border-gray-100 pt-2 pl-2 text-xs opacity-80 min-h-[20px]">
</div>
</details>
<div class="final-answer markdown-body pt-3">
</div>
`;
hasInjectedDetails = true;
}
// --- Populate Content ---
if (hasInjectedDetails) {
const thinkingStepsDiv = messageContentWrapper.querySelector('.thinking-steps-content');
const finalAnswerDiv = messageContentWrapper.querySelector('.final-answer');
if (thinkingStepsDiv) {
thinkingStepsDiv.innerHTML = sanitizeHTML(marked.parse(thinkingSteps + '<span class="streaming-cursor animate-pulse">▋</span>'));
applyHighlightingAndCopyButtons(thinkingStepsDiv);
}
if (finalAnswerDiv) {
finalAnswerDiv.innerHTML = finalAnswer
? sanitizeHTML(marked.parse(finalAnswer))
: '<span class="text-gray-400 text-sm">正在处理...</span>';
applyHighlightingAndCopyButtons(finalAnswerDiv);
}
} else {
messageContentWrapper.innerHTML = sanitizeHTML(marked.parse(finalAnswer + '<span class="streaming-cursor animate-pulse">▋</span>'));
applyHighlightingAndCopyButtons(messageContentWrapper);
}
requestAnimationFrame(() => {
chatArea.scrollTop = chatArea.scrollHeight;
});
}
// --- Handle Stream End ---
if (data.result?.metadata?.finishReason === 'stop' || data.result?.metadata?.finishReason === 'STOP') {
streamEnded = true;
currentEventSource.close();
// --- Final Processing of accumulatedContent ---
const thinkRegex = /<think>(.*?)<\/think>/gs;
let finalThinkingSteps = '';
let match;
const localThinkRegex = /<think>(.*?)<\/think>/gs; // Use new instance
while ((match = localThinkRegex.exec(accumulatedContent)) !== null) {
finalThinkingSteps += match[1] + '\n';
}
finalThinkingSteps = finalThinkingSteps.trim();
const finalFinalAnswer = accumulatedContent.replace(/<think>.*?<\/think>/gs, '').trim();
// --- Final DOM Update ---
messageContentWrapper = document.getElementById(messageId)?.querySelector('.message-content-wrapper');
if (!messageContentWrapper) {
console.error("Message wrapper not found for final update!");
return;
}
messageContentWrapper.querySelectorAll('.streaming-cursor').forEach(c => c.remove());
if (finalThinkingSteps) {
if (!hasInjectedDetails) {
messageContentWrapper.innerHTML = `
<details class="thinking-process" open>
<summary>思考过程 <span class="text-xs opacity-70">(来自历史记录)</span></summary>
<div class="thinking-steps-content markdown-body border-t border-gray-100 pt-2 pl-2 text-xs opacity-80"></div>
</details>
<div class="final-answer markdown-body pt-3"></div>
`;
hasInjectedDetails = true;
}
const thinkingStepsDiv = messageContentWrapper.querySelector('.thinking-steps-content');
const finalAnswerDiv = messageContentWrapper.querySelector('.final-answer');
if (thinkingStepsDiv) {
thinkingStepsDiv.innerHTML = sanitizeHTML(marked.parse(finalThinkingSteps));
applyHighlightingAndCopyButtons(thinkingStepsDiv);
} else {
console.error("Thinking steps div not found in final update!");
}
if (finalAnswerDiv) {
finalAnswerDiv.innerHTML = finalFinalAnswer ? sanitizeHTML(marked.parse(finalFinalAnswer)) : '';
applyHighlightingAndCopyButtons(finalAnswerDiv);
} else {
console.error("Final answer div not found in final update!");
}
// Update summary text after completion
const summaryElement = messageContentWrapper.querySelector('.thinking-process summary');
if (summaryElement) summaryElement.innerHTML = `思考过程 <span class="text-xs opacity-70">(点击展开/折叠)</span>`;
} else {
messageContentWrapper.innerHTML = finalFinalAnswer ? sanitizeHTML(marked.parse(finalFinalAnswer)) : '';
if (!hasInjectedDetails) {
messageContentWrapper.classList.add('markdown-body');
}
applyHighlightingAndCopyButtons(messageContentWrapper);
}
// --- Save the complete message (including <think> tags) ---
// IMPORTANT: Even with the workaround, save the ORIGINAL AI response
// (accumulatedContent) to localStorage, *including* any <think> tags,
// so the history display remains accurate. Don't save the combinedMessage.
if (currentChatId && accumulatedContent.trim()) {
const chatData = getChatData(currentChatId);
if (chatData) {
chatData.messages.push({content: accumulatedContent, isAssistant: true});
localStorage.setItem(`chat_${currentChatId}`, JSON.stringify(chatData));
updateChatList();
}
}
currentEventSource = null;
setStreamingState(false);
messageInput.focus();
}
} catch (e) {
console.error('Error processing stream event:', e, event.data);
}
};
currentEventSource.onerror = function (error) {
// ... (SAME onerror logic as before) ...
console.error('EventSource encountered an error:', error);
streamEnded = true;
if (currentEventSource) {
currentEventSource.close();
}
const errorText = '--- 抱歉,连接中断或发生错误 ---';
messageContentWrapper = document.getElementById(messageId)?.querySelector('.message-content-wrapper');
if (messageContentWrapper) {
messageContentWrapper.querySelectorAll('.streaming-cursor').forEach(c => c.remove());
const errorP = document.createElement('p');
errorP.className = 'text-red-500 text-sm font-semibold mt-2 border-t pt-2';
errorP.textContent = errorText;
const finalAnswerDiv = messageContentWrapper.querySelector('.final-answer');
if (finalAnswerDiv) {
if (finalAnswerDiv.textContent.includes("正在处理")) finalAnswerDiv.innerHTML = '';
finalAnswerDiv.appendChild(errorP);
} else {
if (messageContentWrapper.textContent === '▋') messageContentWrapper.innerHTML = '';
messageContentWrapper.appendChild(errorP);
}
// Update summary text in case of error during thinking display
const summaryElement = messageContentWrapper.querySelector('.thinking-process summary');
if (summaryElement && summaryElement.textContent.includes("思考过程...")) {
summaryElement.innerHTML = `思考过程 <span class="text-xs opacity-70">(已中断)</span>`;
}
} else {
appendMessage(errorText, true, false);
}
currentEventSource = null;
setStreamingState(false);
messageInput.focus();
};
}后端接口改写 generate_stream 方法配合前端调用,实现上下文记忆功能。
/**
* http://localhost:7080/api/v1/openai/generate_stream?model=deepseek-r1:1.5b&message=你是?
*/
@GetMapping("generate_stream")
@Override
public Flux<ChatResponse> generateStream(
@RequestParam("model") String model,
@RequestParam("message") String currentMessage, // 为了清晰,重命名一下
@RequestParam(name = "history", required = false, defaultValue = "[]") String history // 接收 history JSON 字符串
) {
List<Message> conversation = new ArrayList<>(); // 用于存储完整对话的列表
// 尝试解析 history JSON
try {
// 将 JSON 字符串解析为 Map 列表,每个 Map 代表一条消息
List<Map<String, String>> historyList = objectMapper.readValue(history, new TypeReference<List<Map<String, String>>>() {});
for (Map<String, String> msg : historyList) {
// 根据 'role' 创建相应的 Message 对象
if ("user".equalsIgnoreCase(msg.get("role"))) {
conversation.add(new UserMessage(msg.get("content")));
} else if ("assistant".equalsIgnoreCase(msg.get("role"))) {
// 如果历史记录中保存了 <think> 标签,也一并包含
conversation.add(new AssistantMessage(msg.get("content")));
}
}
} catch (Exception e) {
// 记录错误或处理无效的 history JSON - 可以考虑返回一个错误的 Flux?
System.err.println("解析聊天历史 JSON 时出错: " + e.getMessage());
// 为简单起见,如果解析失败,则在没有历史记录的情况下继续
}
// 添加当前用户发送的消息
conversation.add(new UserMessage(currentMessage));
// 使用完整的对话历史创建 Prompt
Prompt prompt = new Prompt(
conversation, // 传入包含所有消息的 List<Message>
OllamaOptions.builder()
.model(model)
.build()
);
// 将包含完整对话的 Prompt 发送给模型
return openAiChatModel.stream(prompt);
}OllamaController 中的方法按照此修改。
二、部署过程
下图为本次部署的过程;

从本地开发到云端部署,流程为:开发 → 构建Docker镜像 → 推送至Docker Hub → 云端拉取镜像 → 运行Spring Boot应用并依赖支持服务执行。
三、项目部署
1. 工程结构
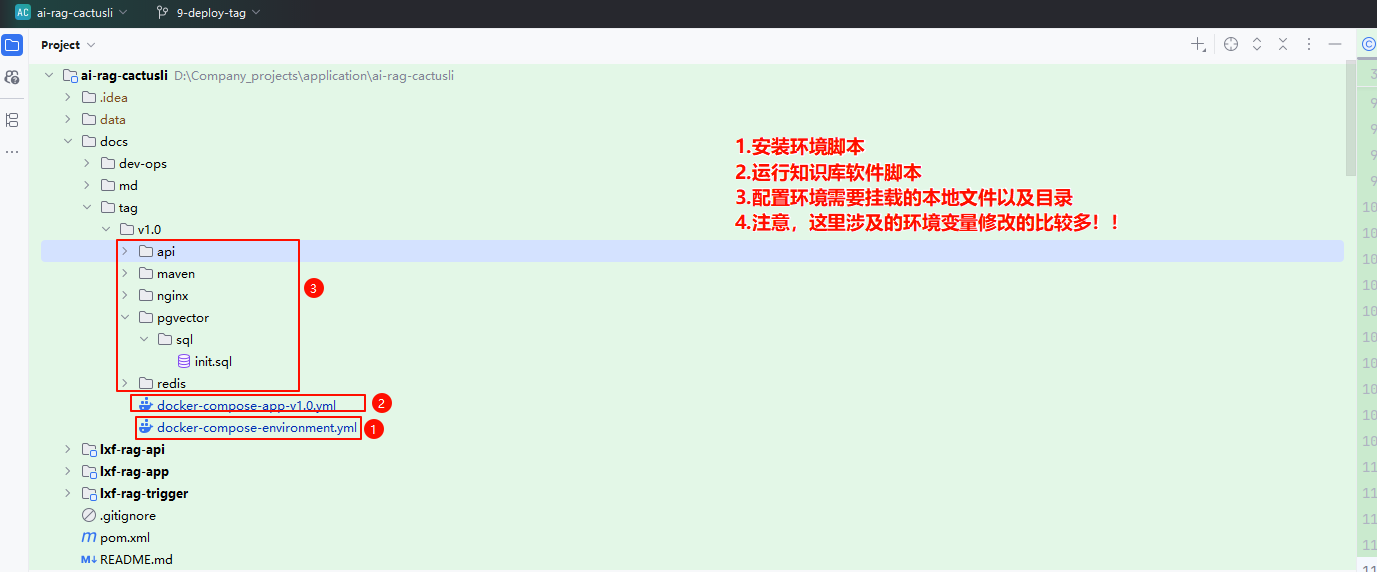
2. 镜像构建
本地安装了 Docker Desktop 直接运行 lxf-rag-app/build.sh 脚本即可。
Docker 部署在云服务云服务器上,需要通过开始 Docker Engine API来访问操作 Docker。
查询 docker.service 配置路径:
systemctl show -p FragmentPath docker.service编辑 docker.service 开启 Docker Engine API
vim /lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target docker.socket firewalld.service containerd.service time-set.target
Wants=network-online.target containerd.service
Requires=docker.socket
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
# 注释原来的内容(添加 tcp://0.0.0.0:4610 -H unix:///var/run/docker.sock)
#ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:4610 -H unix:///var/run/docker.sock
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutStartSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
OOMScoreAdjust=-500
[Install]
WantedBy=multi-user.target重启 Docker :
sudo systemctl daemon-reload
sudo systemctl restart docker安装 Docker 插件:
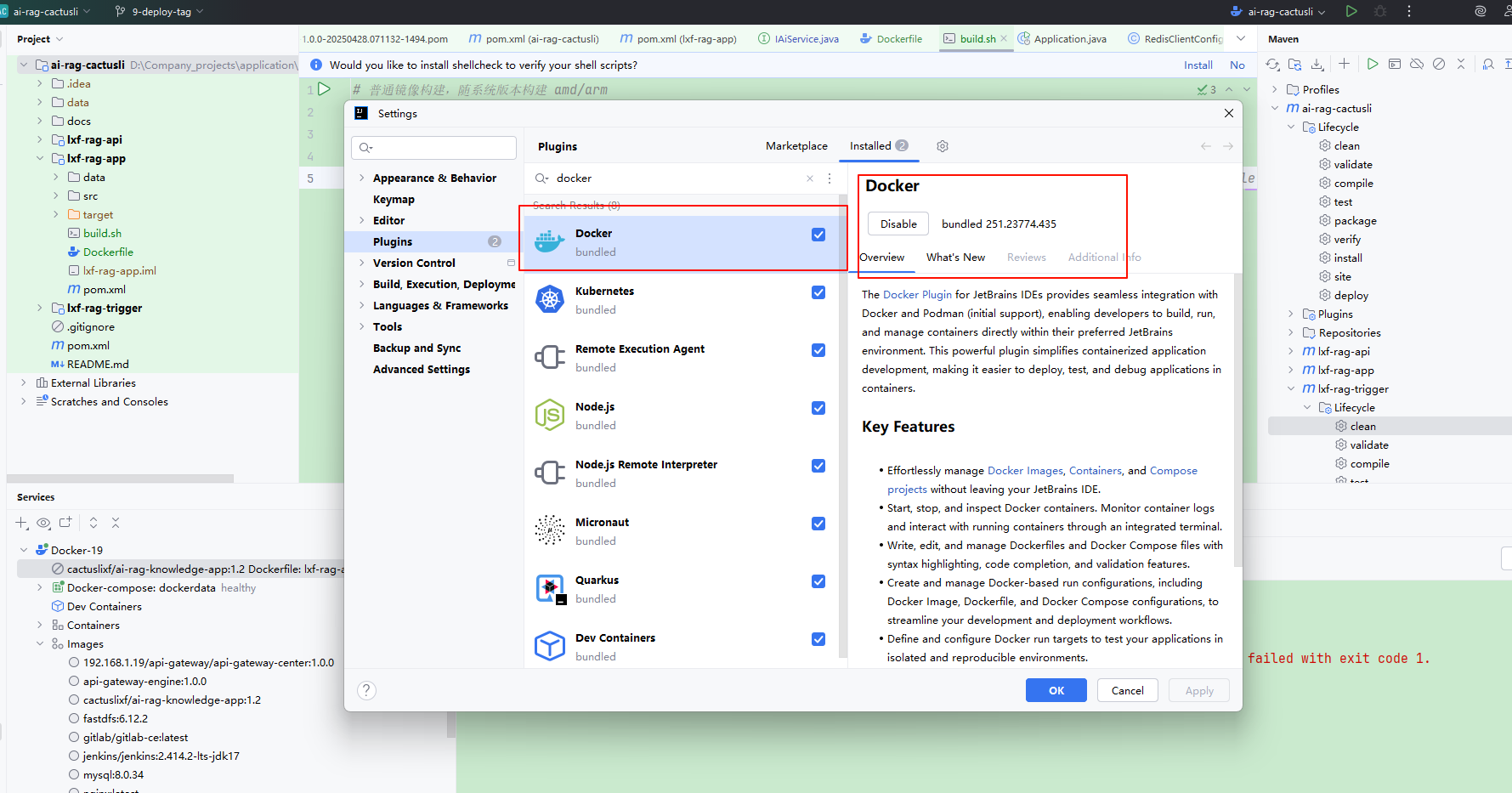
在 Idea 中添加 Docker Engine API 的访问路径:
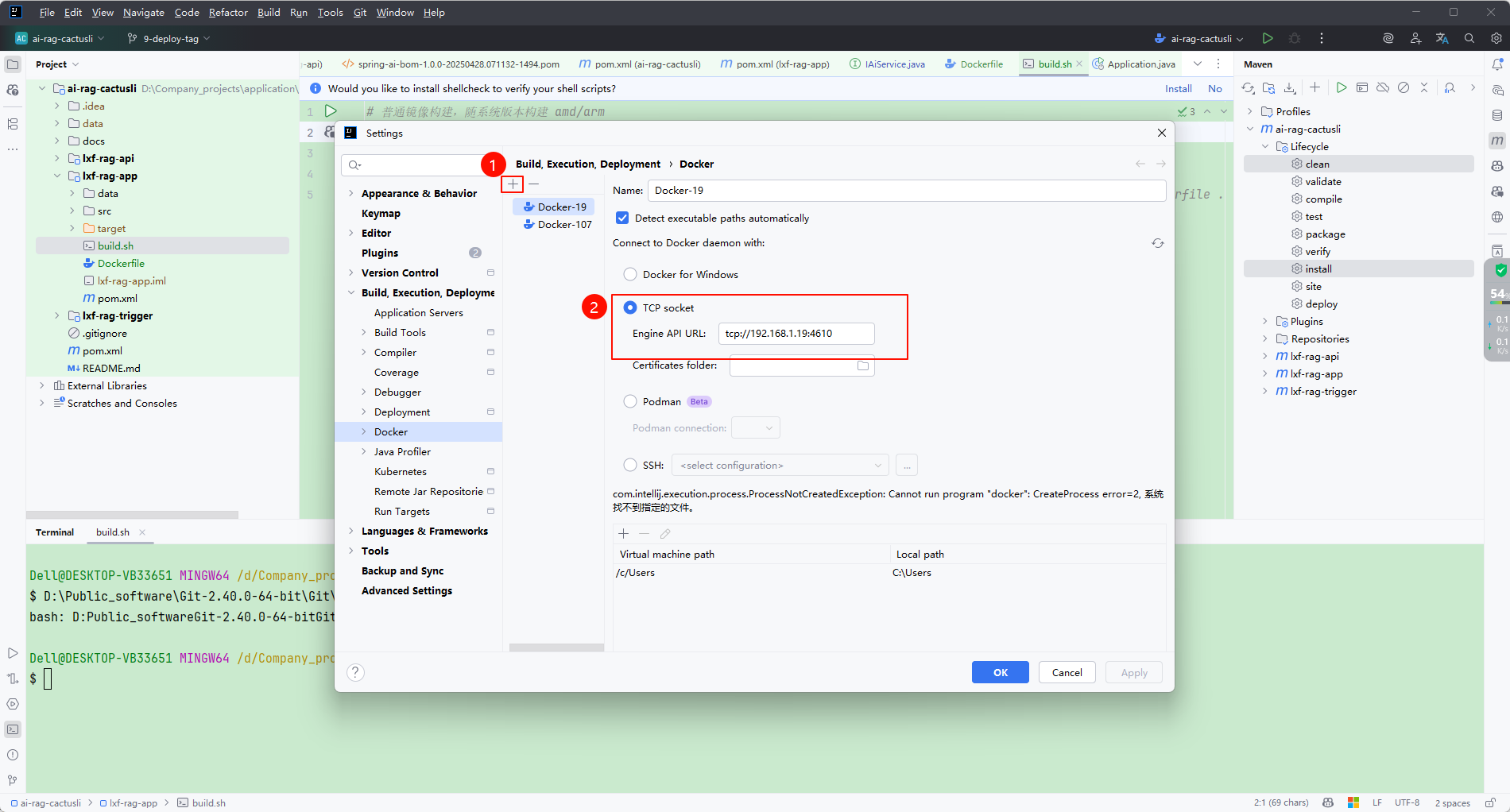
上图出现了:com.intellij.execution.process.ProcessNotCreatedException: Cannot run program "docker": CreateProcess error=2, 系统找不到指定的文件 的错误,这是因为新本本的 idea 需要配置 Docker CLI 了。
下载 Docker CLI
- 访问 Docker 官方静态二进制文件下载页面:https://download.docker.com/win/static/stable/x86_64/。
将 Docker CLI 添加到系统路径
- 将 docker.exe 移动到一个固定目录,例如 C:\docker。
- 将该目录添加到系统环境变量 Path 中:
- 右键“此电脑” → “属性” → “高级系统设置” → “环境变量”。
- 在“系统变量”中找到 Path,点击“编辑”,添加 C:\docker。
- 打开命令提示符,运行
docker --version确认安装成功。
配置 IntelliJ IDEA
选中配置好的
docker.exe: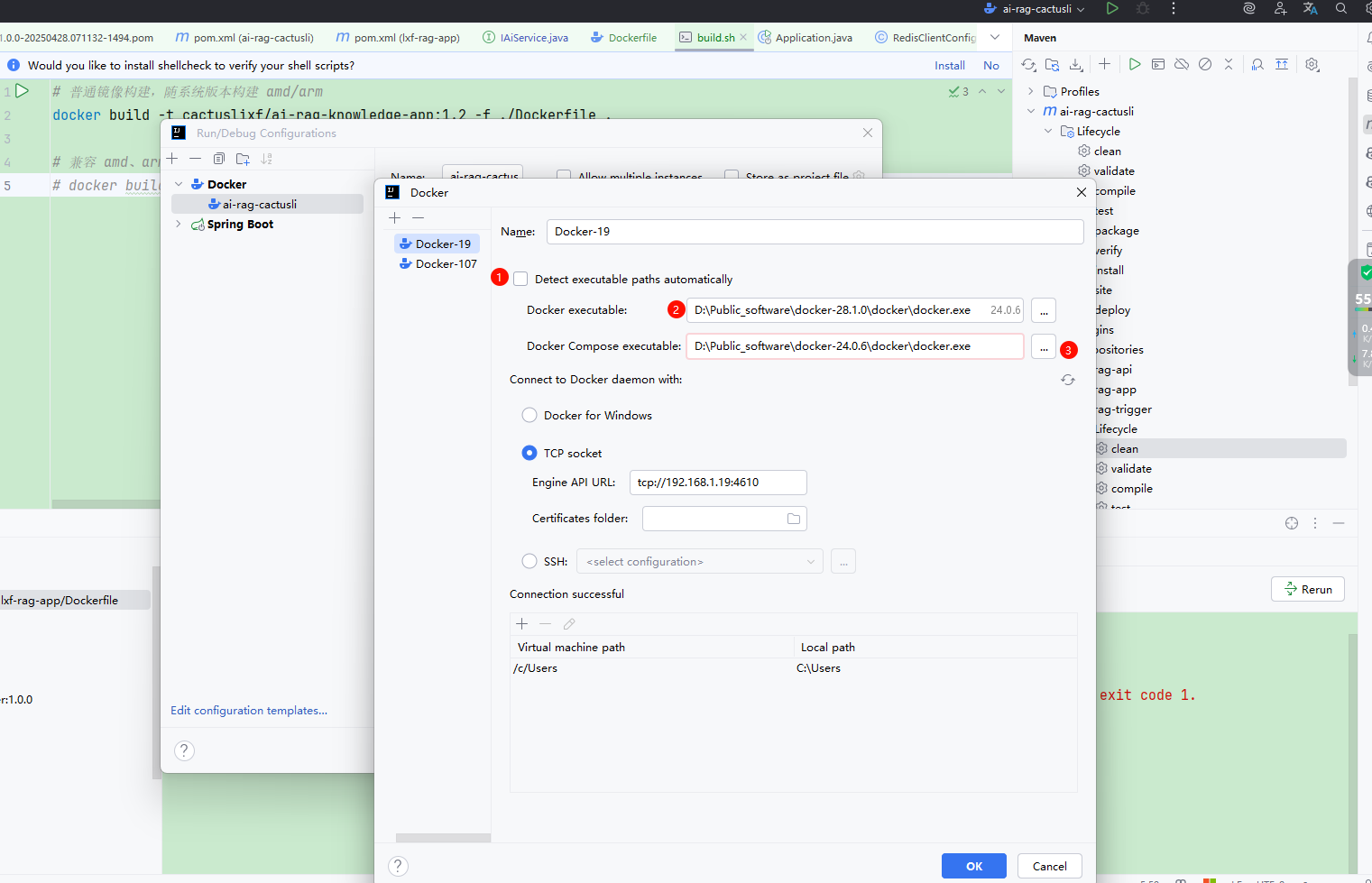
image-20250430165131488
在开始构建镜像时如果出现以下错误,需要下载并配置 buildx工具。
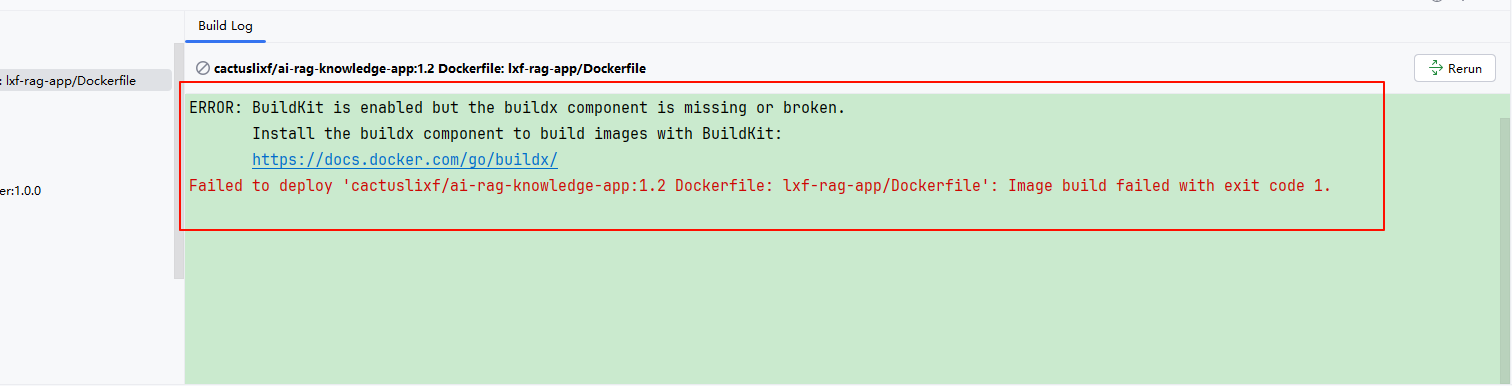
下载地址:https://github.com/docker/buildx/releases/tag/v0.23.0
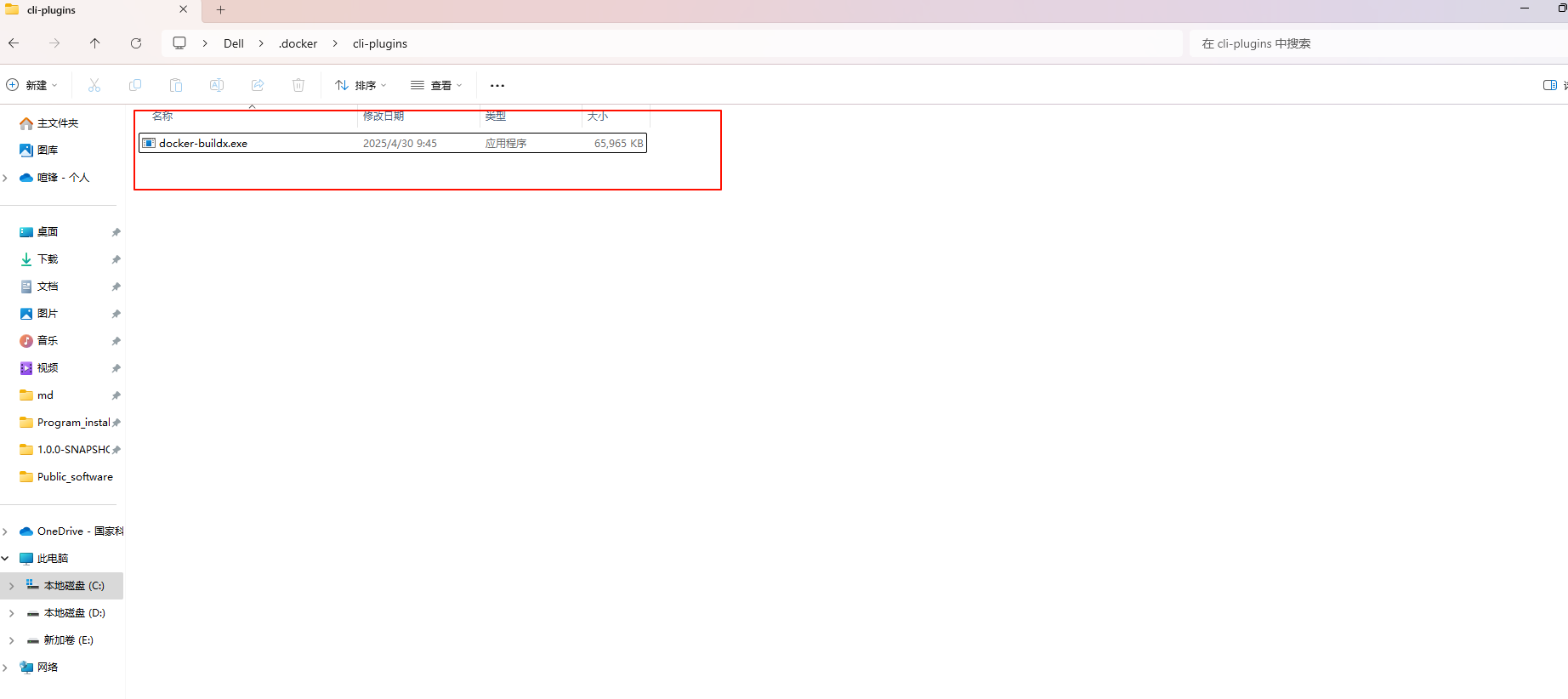
在用户文件夹下(或在文件管理地址栏输入 %USERPROFILE% 定位),新建 .docker 文件夹(注意有个“.”),下面再新建一个cli-plugins文件夹,把下载好的文件重命名 docker-buildx.exe,然后放入到该目录下。
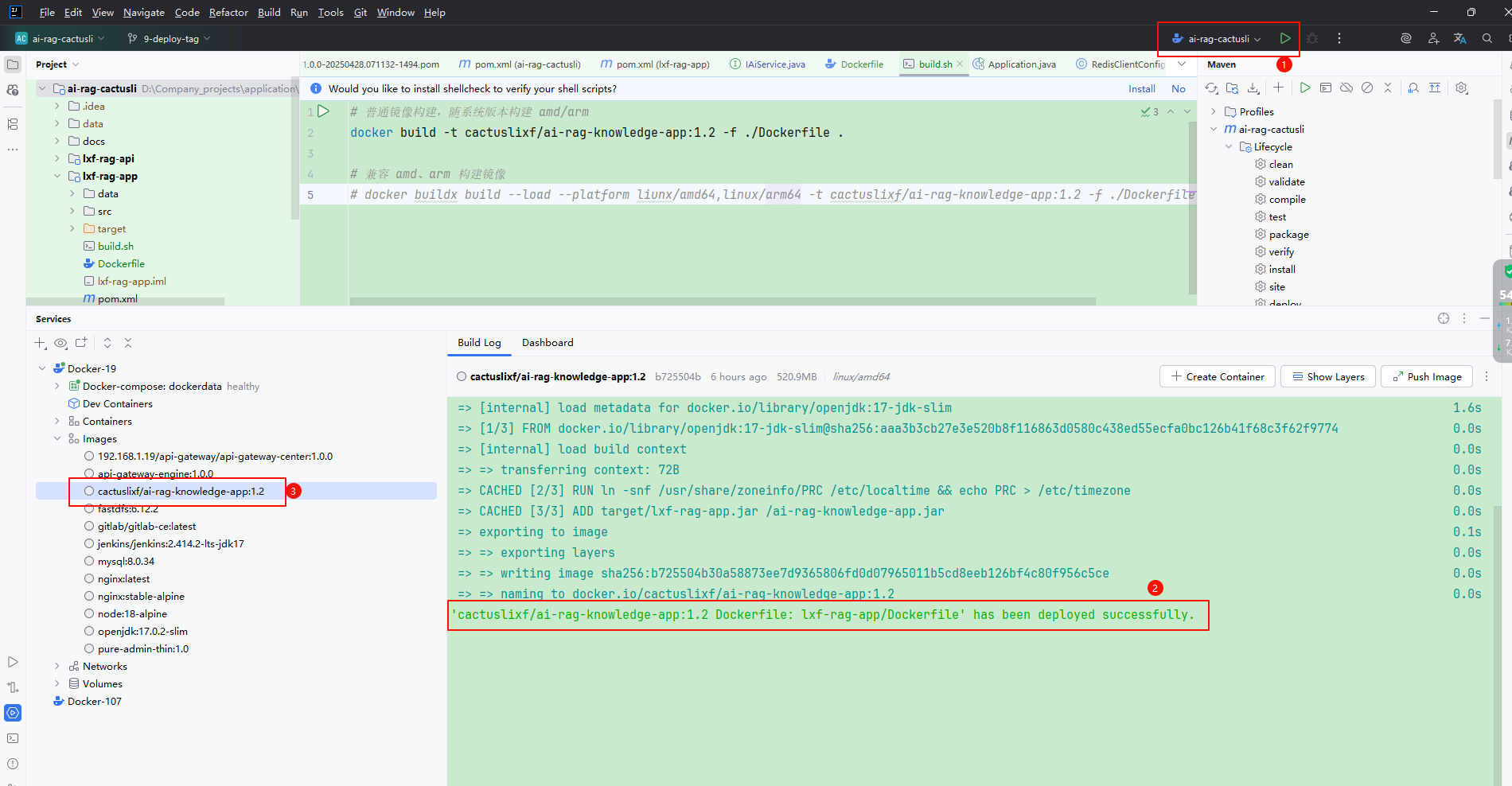
解决完所有错误后进行构建,输出以下内容代表镜像构建成功:
3. 操作脚本
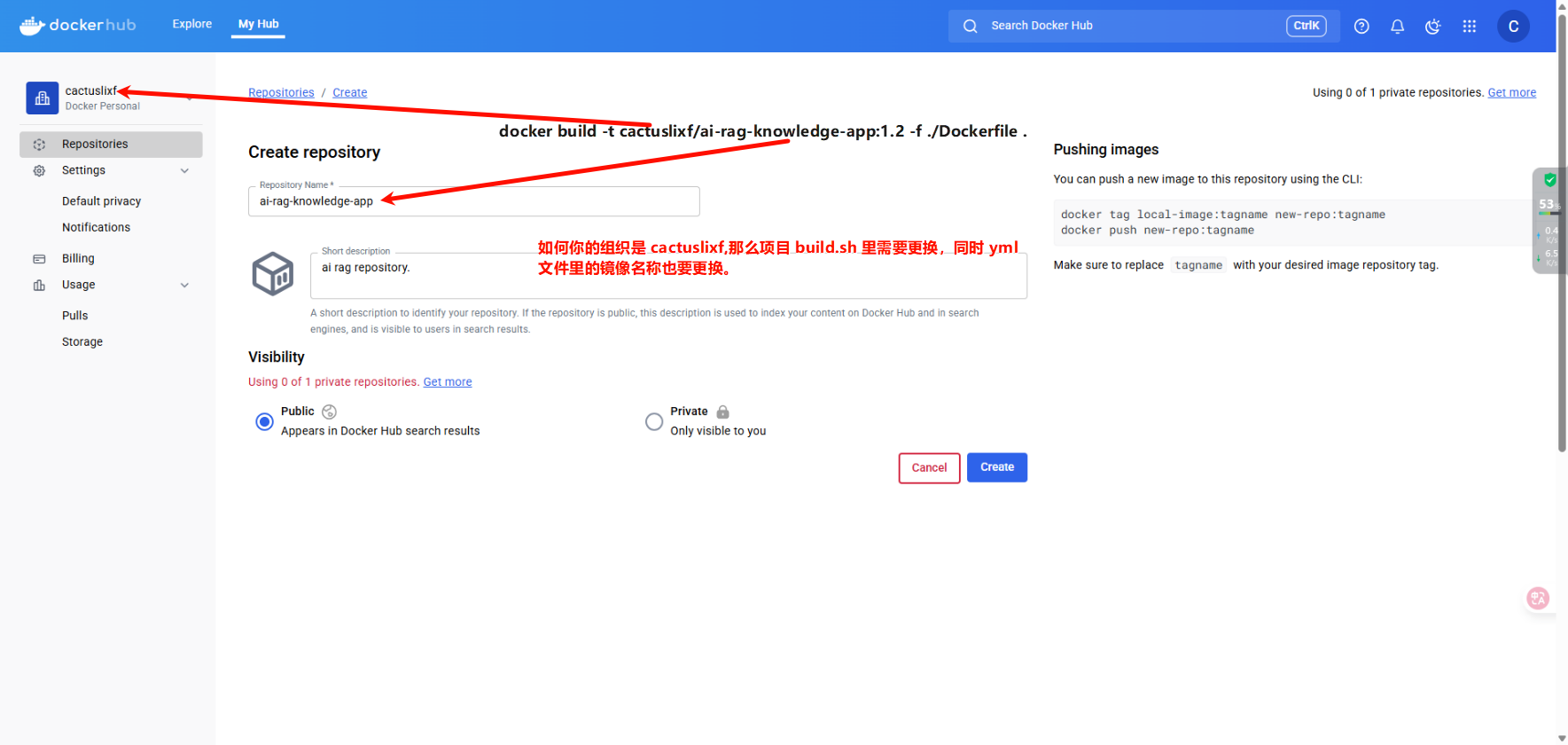
- 在 https://hub.docker.com/repository/create 创建你的镜像名称。(需要开代理才能打开)
- Linux 代理软件开源地址:https://github.com/nelvko/clash-for-linux-install
4. 上传镜像
通过命令方式将镜像推送至 Docker hub,也可以使用本地 Docker 软件进行上传。
$ docker login -u cactuslixf
$ docker push cactuslixf/ai-rag-knowledge-app:1.2如下图是上传成功的案例:

注意需要开启代理才能 push 成功!也可以购买一台国外的 vps 来验证操作。
Linux 代理软件开源地址:https://github.com/nelvko/clash-for-linux-install
5. 上传脚本

将文件全部上传到指定目录下。
6. 执行脚本
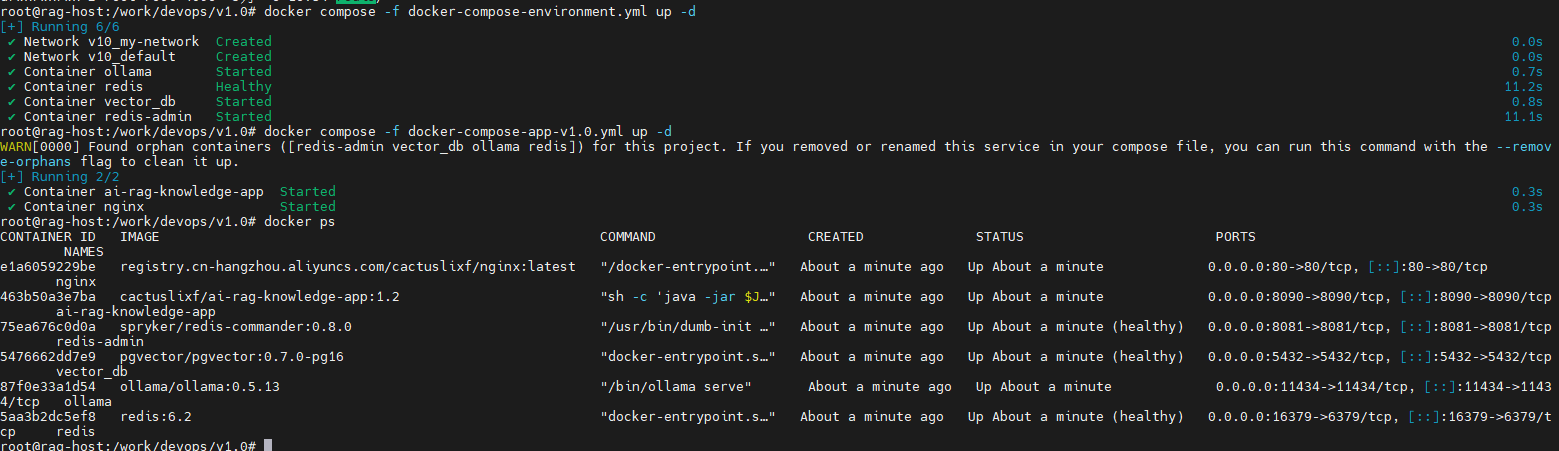
8. 访问服务
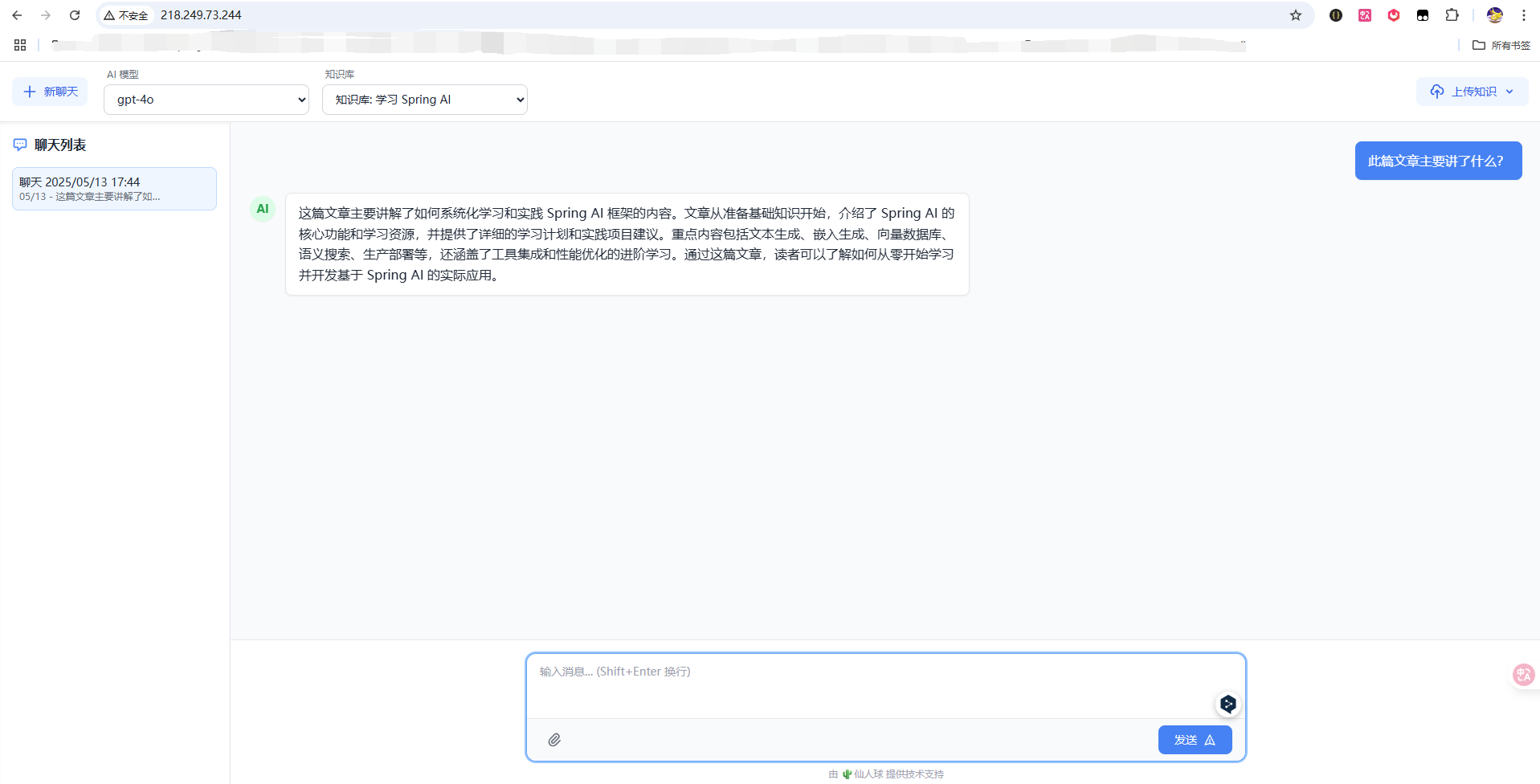
至此,就成功搭建了自己的私有本地知识库!