RAG 知识库上传、解析和验证
一、介绍
以大模型向量存储的方式,将本地文件自定义方式组成知识库。并在 AI 对话中增强检索知识库符合 AI 对话内容的资料,合并提交问题。
二、技术方案
本技术方案利用 Spring AI 提供的向量模型处理框架,首先通过 TikaDocumentReader 解析上传的文件,再使用 TokenTextSplitter 对文件内容进行拆分。完成这些操作后,在对拆分后的文档进行标记,以便区分不同的知识库内容。标记的作用是为了可以区分不同的知识库内容。完成这些动作后,把这些拆解并打标的文件存储到 postgresql 向量库中。
本技术方案旨在利用 Spring AI 提供的向量模型处理框架,对上传的文件进行解析、拆分、标记,并将处理后的数据存储到 PostgreSQL 向量库中。通过这一流程,可以实现对文件内容的高效管理和检索,特别是在需要区分不同知识库内容的场景下。
1. 技术组件
- SpringAI : 提供向量模型处理框架,支持文件的解析、拆分和向量化操作。
- TikaDocumentReader : 是一种基于 Apache Tika 的文档解析器。Apache Tika 是一个用于自动化提取文档内容的库,支持各种格式的文件(如 PDF、Word、Excel、HTML、XML 等)的解析。
- TokenTextSplitter : 是一种文本拆分工具,通常用于将长文本分割成更小的单元,以便进行更有效的处理(如向量化)。该工具的工作原理是根据词汇单元(tokens)将长文本切割成较小的部分。拆分后的文本可以用于计算机处理,例如创建文本的向量表示或构建索引,以支持高效的检索。
- PostgreSQL向量库 : 用于存储处理后的文本向量数据,支持高效的相似性搜索和检索。
2. 方案流程
2.1 文件上传与解析
- 文件上传 : 用户通过前端界面或 API 上传文件,文件可以是多种格式(如 MD、TXT、SQL 等)。
- 文件解析 : 使用
TikaDocumentReader对上传的文件进行解析,提取出文本内容。TikaDocumentReader能够处理多种文件格式,并提取出结构化的文本数据。
2.2 文本拆分
- 文本拆分 : 使用
TokenTextSplitter将解析后的文本内容拆分为更小的片段。拆分策略可以根据需求进行调整,例如按句子、段落或固定长度的 token 进行拆分。 - 拆分后的文本片段 : 每个文本片段将作为后续处理和存储的基本单元。
2.3 文本标记
- 标记添加 : 在遍历拆分后的文本片段时,为每个片段添加标记。标记的作用是区分不同的知识库内容,例如通过标记标识文件的来源、类别或其他元数据信息。
- 标记格式 : 标记可以是简单的字符串标签,也可以是结构化的 JSON 数据,具体格式根据业务需求确定。
2.4 向量化与存储
- 向量化 : 使用 Spring AI 提供的向量模型将标记后的文本片段转换为向量表示。向量化过程将文本内容映射到高维向量空间,便于后续的相似性搜索和检索。
- 存储到PostgreSQL向量库 : 将向量化后的文本片段及其标记存储到 PostgreSQL 向量库中。PostgreSQL 提供了高效的向量索引和搜索功能,能够支持大规模的文本数据存储和检索。
3. 使用场景
- 知识库管理 : 适用于需要管理多个知识库内容的场景,通过标记区分不同来源的知识库。
- 文档检索 : 支持基于内容的文档检索,通过向量化实现高效的相似性搜索。
- 智能问答 : 适用于构建智能问答系统,通过向量化存储和检索实现快速的知识匹配。
- 代码评审 :结合代码库,评审具体的代码块,会更加准确。
- 编程开发 :可用于编程开发中需求理解、代码查询、流程图等。
三、具体实现
1. 项目结构

2. 引入文档解析存储组件
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>spring-ai-tika-document-reader 解析文档组件,spring-ai-pgvector-store-spring-boot-starter 向量存储库组件。
3. application-dev.yml 配置
server:
port: 7080
spring:
datasource:
driver-class-name: org.postgresql.Driver
username: postgres
password: postgres
url: jdbc:postgresql://192.168.1.107:5432/ai-rag-cactusli
type: com.zaxxer.hikari.HikariDataSource
# hikari连接池配置
hikari:
#连接池名
pool-name: HikariCP
#最小空闲连接数
minimum-idle: 5
# 空闲连接存活最大时间,默认10分钟
idle-timeout: 600000
# 连接池最大连接数,默认是10
maximum-pool-size: 10
# 此属性控制从池返回的连接的默认自动提交行为,默认值:true
auto-commit: true
# 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认30分钟
max-lifetime: 1800000
# 数据库连接超时时间,默认30秒
connection-timeout: 30000
# 连接测试query
connection-test-query: SELECT 1
ai:
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE
dimensions: 768
batching-strategy: TOKEN_COUNT # Optional: Controls how documents are batched for embedding
max-document-batch-size: 10000 # Optional: Maximum number of documents per batch
ollama:
base-url: http://192.168.1.107:11434
embedding:
options:
num-batch: 512
model: nomic-embed-text
# Redis
redis:
sdk:
config:
host: 192.168.1.107
port: 16379
pool-size: 10
min-idle-size: 5
idle-timeout: 30000
connect-timeout: 5000
retry-attempts: 3
retry-interval: 1000
ping-interval: 60000
keep-alive: true
logging:
level:
root: info
config: classpath:logback-spring.xml通过属性ai.ollama.embedding.model 可以指定向量库模型,这个是 ollama 安装的模型。
spring.datasource 配置 postgresql 地址。注意,这里为了避免端口冲突,设置为 15432,和 docker compose 设置的对外端口一致。
4. 配置向量存储
在启动时,PgVectorStore 将尝试安装所需的数据库扩展,并使用索引。
创建所需的 vector_store 表:
# 安装 vector 扩展,它为 PostgreSQL 添加向量数据类型和相关操作。这是处理嵌入向量的基础扩展
CREATE EXTENSION IF NOT EXISTS vector;
# 安装 hstore 扩展,它提供了键值对存储功能,可用于存储元数据
CREATE EXTENSION IF NOT EXISTS hstore;
# 安装 uuid-ossp 扩展,它提供了生成 UUID (通用唯一标识符) 的功能
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
# 创建名为 vector_store 的表,包含四个字段:
# id: UUID 类型的主键,默认使用 uuid_generate_v4() 函数自动生成
# content: 文本内容字段,可能存储与嵌入向量关联的原始文本
# metadata: JSON 类型字段,用于存储相关元数据
# embedding: 768 维的向量字段,通常用于存储模型生成的嵌入向量(如 OpenAI 的嵌入模型默认输出 1536 维向量)
CREATE TABLE IF NOT EXISTS vector_store (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
content text,
metadata json,
embedding vector(768)
);
# 在 vector_store 表的 embedding 字段上创建一个 HNSW (Hierarchical Navigable Small World) 索引,并指定使用余弦相似度作为向量比较的度量方式。这种索引大大加速了向量相似性搜索,允许快速找到与查询向量最相似的向量,这是实现高效向量搜索的关键
CREATE INDEX ON vector_store USING HNSW (embedding vector_cosine_ops);Spring AI 提供了简单 SimpleVectorStore 实现类,把文档信息缓存到内存中。还提供了 PgVectorStore 实现类,把文档存储到向量库。这块的需要现在 app.config.OllamaConfig.java 中,实例化 VectorStore 存储实现类。
@Configuration
public class OllamaConfig {
@Bean
public OllamaApi ollamaApi(@Value("${spring.ai.ollama.base-url}") String baseUrl) {
return new OllamaApi(baseUrl);
}
@Bean
public OllamaChatModel ollamaChatModel(OllamaApi ollamaApi) {
return OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(
OllamaOptions.builder()
.temperature(0.9)
.build())
.build();
}
/**
* 配置文本分割器。
* 这个Bean负责创建文本分割工具,可以把长文本切分成小段落。
* 在做文档检索时,通常需要先把文档分成小块再处理,这个分割器就是干这个的。
*/
@Bean
public TokenTextSplitter tokenTextSplitter() {
return new TokenTextSplitter();
}
/**
* 配置内存向量存储。
*
* 这个Bean创建一个内存中的向量数据库,用来存储和检索文本的向量表示。
* 它使用Ollama的API将文本转换为向量,并用nomic-embed-text模型生成这些向量。
* 适合小规模应用或测试使用。
*
* @param ollamaApi AI模型服务的接口
* @return 返回一个可以在内存中存储向量的数据库
*/
@Bean
public SimpleVectorStore simpleVectorStore(OllamaApi ollamaApi) {
// 嵌入生成客户端指定使用"nomic-embed-text"这个模型来生成嵌入向量
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(
OllamaOptions.builder()
.model(NOMIC_EMBED_TEXT)
.build())
.build();
return SimpleVectorStore.builder(embeddingModel).build();
}
/**
* 配置PostgreSQL向量存储。
* 这个Bean创建一个基于PostgreSQL的向量数据库,适合存储大量数据和生产环境使用。
* 它同样使用Ollama的API生成向量,但会把这些向量保存在PostgreSQL数据库中。
* 使用前需要确保PostgreSQL已安装vector扩展。
* @param ollamaApi AI模型服务的接口
* @param jdbcTemplate 数据库连接工具
* @return 返回一个可以在PostgreSQL中存储向量的数据库
*/
@Bean
public PgVectorStore pgVectorStore(OllamaApi ollamaApi, JdbcTemplate jdbcTemplate) {
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(
OllamaOptions.builder()
.model(NOMIC_EMBED_TEXT)
.build())
.build();
return PgVectorStore.builder(jdbcTemplate, embeddingModel).build();
}
}
- SimpleVectorStore,把知识库缓存到内存
- PgVectorStore,把知识库通过 JdbcTemplate 也就是 pgsql 操作,存储到向量库
- TokenTextSplitter,用于切割文本的操作
5. 将知识上传至向量库
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class RAGTest {
@Resource
private OllamaChatModel ollamaChatModel;
@Resource
private TokenTextSplitter tokenTextSplitter;
@Resource
private SimpleVectorStore simpleVectorStore;
@Resource
private PgVectorStore pgVectorStore;
@Test
public void uploadKnowledgeBase() {
log.info("开始上传文档处理...");
log.info("正在读取文件: ./data/file.text");
TikaDocumentReader reader = new TikaDocumentReader("./data/file.text");
List<Document> documents = reader.get();
log.info("文档读取完成,原始文档数量: {}", documents.size());
log.info("开始文档切分...");
List<Document> documentSplitterList = tokenTextSplitter.apply(documents);
log.info("文档切分完成,切分后文档数量: {}", documentSplitterList.size());
log.info("为文档添加元数据标记...");
documents.forEach(doc -> doc.getMetadata().put("cactusli", "知识库名称"));
documentSplitterList.forEach(doc -> doc.getMetadata().put("cactusli", "知识库名称"));
log.info("元数据添加完成");
log.info("开始向PostgreSQL向量数据库写入文档...");
pgVectorStore.accept(documentSplitterList);
log.info("文档处理完成,共处理文档{}个,切分后文档{}个", documents.size(), documentSplitterList.size());
}
}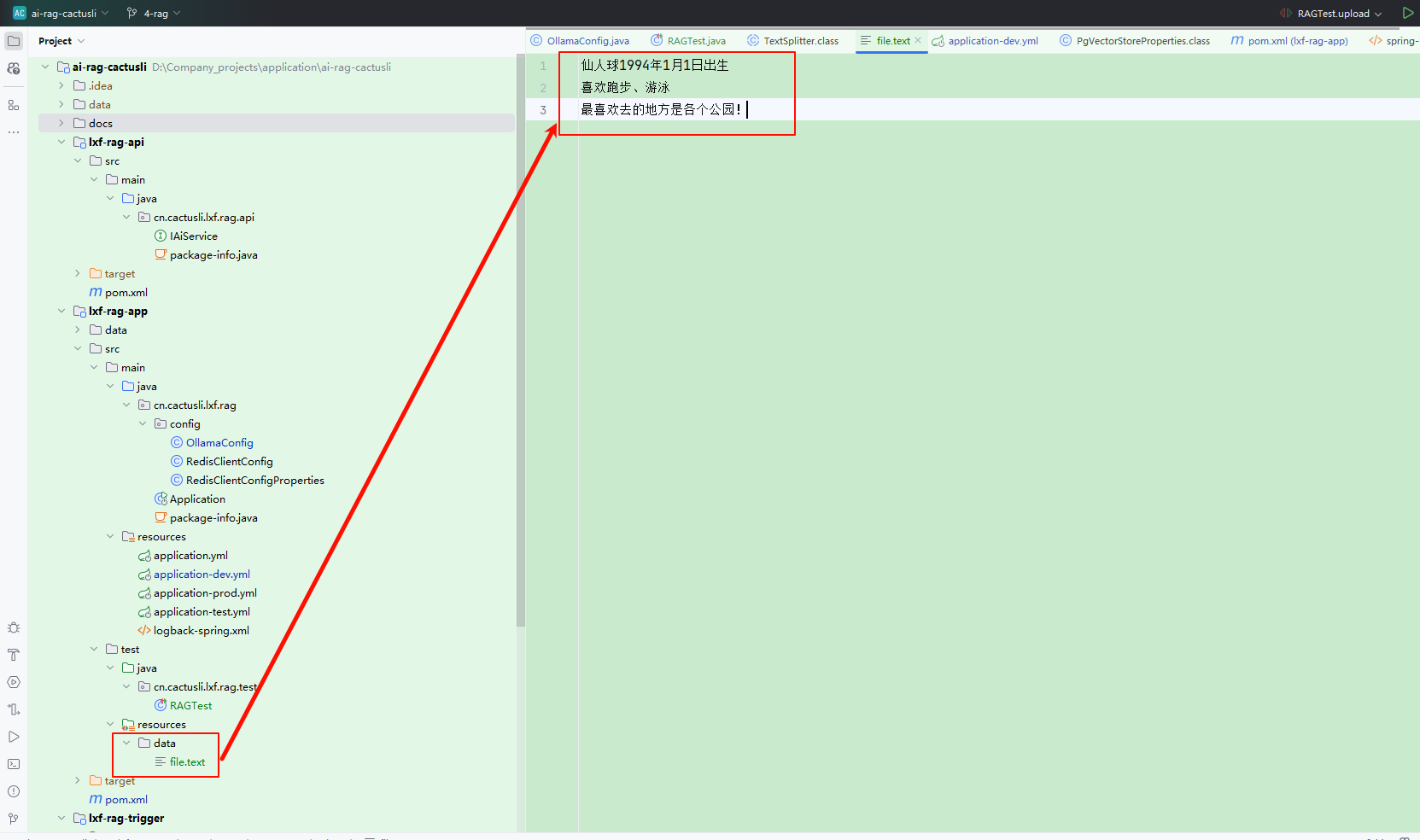
uploadKnowledgeBase 是上传知识库到向量数据库的操作,在这里是将本地 ./data/file.txt 文件,转换为 TikaDocumentReader 进行读取。读取到文件后在进行切割和设置文件标记,写上知识库名称。
在这里是过 PgVectorStore 存储到向量库中。如果你这里用 simpleVectorStore 就是存储到程序内存,关闭程序后则消失。
6. 检索知识库
@Test
public void ragChat() {
String message = "仙人球, 哪年出生的";
log.info("用户提问: {}", message);
String SYSTEM_PROMPT = """
Use the information from the DOCUMENTS section to provide accurate answers but act as if you knew this information innately.
If unsure, simply state that you don't know.
Another thing you need to note is that your reply must be in Chinese!
DOCUMENTS:
{documents}
""";
log.info("系统提示模板已设置");
log.info("开始向量数据库相似度搜索,查询: {}", message);
SearchRequest request = SearchRequest.builder().query(message).topK(5).filterExpression("cactusli == '知识库名称'").build();
log.info("搜索参数: topK={}, 过滤条件={}", 5, "cactusli == '知识库名称'");
List<Document> documents = pgVectorStore.similaritySearch(request);
log.info("搜索完成,找到相关文档数量: {}", documents.size());
for (int i = 0; i < documents.size(); i++) {
log.info("文档[{}]内容片段: {}", i + 1, documents.get(i).getText().substring(0, Math.min(50, documents.get(i).getText().length())) + "...");
}
String documentsCollects = documents.stream().map(Document::getText).collect(Collectors.joining());
log.info("合并文档总长度: {} 字符", documentsCollects);
log.info("创建RAG系统消息...");
Message ragMessage = new SystemPromptTemplate(SYSTEM_PROMPT).createMessage(Map.of("documents", documentsCollects));
ArrayList<Message> messages = new ArrayList<>();
messages.add(new UserMessage(message));
messages.add(ragMessage);
log.info("消息准备完成,共 {} 条消息", messages.size());
log.info("开始调用Ollama模型 deepseek-r1:1.5b...");
ChatResponse chatResponse = ollamaChatModel.call(new Prompt(messages, ChatOptions.builder().model("deepseek-r1:1.5b").build()));
log.info("Ollama模型调用完成,返回消息: {}", chatResponse.getResult().getOutput().getText());
log.info("完整响应: {}", JSON.toJSONString(chatResponse));
}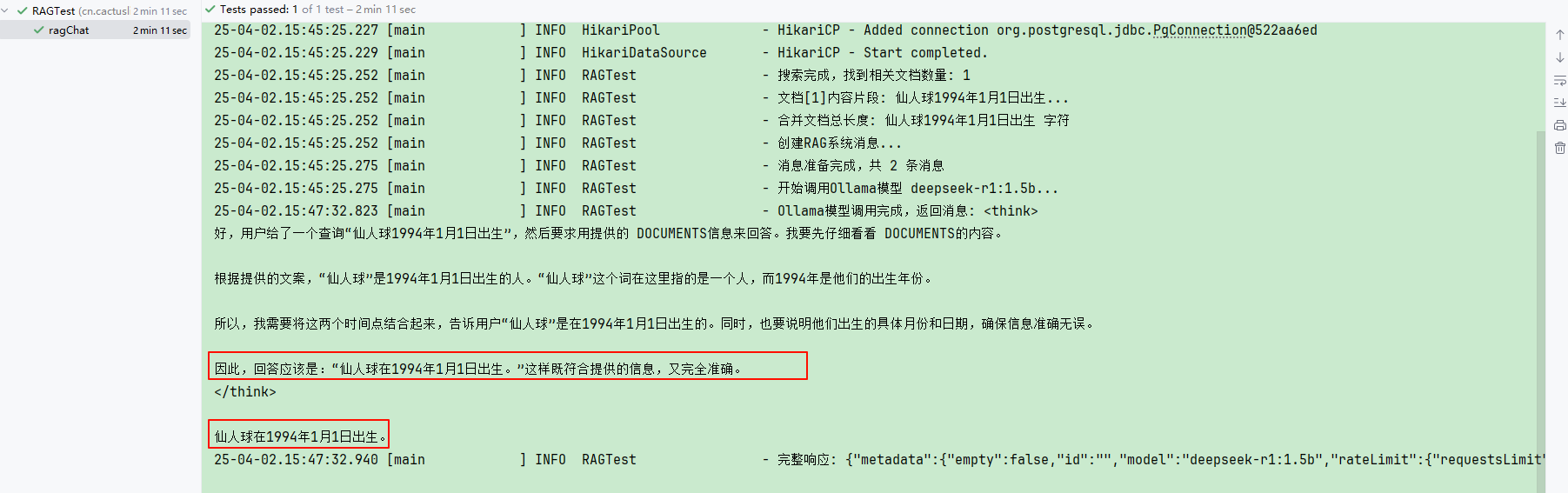
在已有知识库的情况下,我们提问的方式就可以从知识库通过向量方式检索出匹配的信息,之后一起作为问题提问。
至此检索知识库的功能就实现了,自己可以上传一个自定义的知识库,之后验证检索知识库的准确性。